

Deep Dive into Amazon DynamoDB: Unraveling Key Features
Introduction
In every project that needs of database management, the choice between SQL and NoSQL databases is crucial, with considerations ranging from data structure to scalability. Among the NoSQL options, DynamoDB is the serverless NoSQL solution provided by AWS.
NoSQL vs SQL
DynamoDB’s core strength lies in its NoSQL nature, which allows for a schema-less approach. Traditional SQL databases rely on predefined structures for each table, posing challenges when dealing with datasets that have unstructured and evolving data. DynamoDB, with its dynamic and document-oriented design, excels precisely in scenarios where different entities may have distinct attributes within rows.
DynamoDB stores data in a flexible, JSON-like format. This flexibility enables each item (equivalent to a row in SQL) to have different attributes without compromising performance.
When to choose Dynamo:
- Dynamic and Evolving Data: Choose DynamoDB when dealing with datasets that have varying attributes or when the data schema evolves over time.
- JSON-Centric Workloads: If your application primarily deals with JSON data, DynamoDB’s native support makes it an excellent choice for streamlined development and efficient data management.
- Scalability Requirements: DynamoDB is designed for seamless scalability, making it an ideal choice for applications anticipating rapid growth and fluctuating workloads.
- Real-time Data Capture: For scenarios requiring real-time data capture and change tracking, DynamoDB Streams provide a powerful solution.
When NOT to choose Dynamo:
- Complex Joins and Transactions: DynamoDB is designed for simplicity and scalability, and it sacrifices complex join operations and transactions for these benefits. If your application heavily relies on complex SQL join operations or requires ACID-compliant transactions, DynamoDB may not be the best fit. SQL databases with their relational capabilities might be more suitable for such scenarios.
- Structured Data with Fixed Schema: If your application deals with highly structured data with a fixed schema that rarely changes, the flexibility provided by DynamoDB’s schema-less approach may not be necessary. In such cases, a traditional SQL database might be more appropriate, offering the advantages of predefined structures and relationships.
- Limited Query Complexity: If your application relies heavily on complex queries beyond simple key lookups, and you require features like aggregations, grouping, and filtering on non-key attributes, DynamoDB’s query capabilities may fall short. SQL databases, with their SQL query language, might be more suited for intricate querying needs.
Throughput: Read and Write Capacity Units (RCU & WCU)
DynamoDB offers two distinct capacity modes, each addressing different needs:
- Provisioned Mode;
- On-Demand Mode.
In the Provisioned Mode, developers specify the read and write capacity units (RCU and WCU) based on their workload. This allows precise capacity planning, and users only pay for the provisioned capacity. On the other hand, the On-Demand Mode automatically scales up and down, eliminating the need for manual capacity planning but at a higher cost.
In DynamoDB it’s possible to switch between these modes every 24 hours accommodates changing requirements.
DynamoDB has the concept of “burst capacity,” allowing temporary capacity exceedance without throttling. Automatic retries through exponential backoff, particularly when using the AWS SDK, mitigate the impact of exceeding burst capacity.
Write Capacity Unit (WCU):
In DynamoDB, a Write Capacity Unit (WCU) indicates the capability to handle one write operation per second for a 1KB item. Notably, the consumption of WCUs scales proportionally with item size, rounding up to the nearest kilobyte.
Read Capacity Unit (RCU):
To comprehend how DynamoDB consumes Read Capacity Units (RCUs), it’s essential to understand the two primary types of DynamoDB reads: Strongly Consistent Reads and Eventually Consistent Reads.
Strongly Consistent Reads:
- Double Consumption: Strongly consistent reads use double the RCUs compared to the Eventually Consistent Reads.
- Always Up-to-Date: They guarantee you’re getting the latest, most accurate data.
- Use Case Use strongly consistent reads when you really need the most recent information, even though it costs a bit more.
Eventually Consistent Reads:
- Default Setting: DynamoDB usually uses this type, where data might not be the absolute latest.
- Cheaper These reads use half the RCUs compared to the other type.
- Good for Regular Use: If having the absolute latest data isn’t critical, go for these to save on costs.
So you have that:
- 1 RCU represent one strongly consistent read per second for an item of 4KB (With 1RCU you can make 1 read operation of 4KB);
- 1 RCU represent two eventually consistent read per second for an item of 4KB (With 1RCU you can make 2 read operation of 4KB).
These two choices give you control the read consistency, letting you balance accuracy and cost-effectiveness based on what your application needs.
Specifying Read Consistency in DynamoDB Requests:
For read operations like GetItem, Query, and Scan in DynamoDB, you have the flexibility to include an optional parameter called ConsistentRead. When you set ConsistentRead to true, DynamoDB ensures that the response contains the most current data, reflecting updates from all preceding successful write operations.
# Perform a strongly consistent read using GetItem
response = dynamodb.get_item(
TableName=table_name,
Key=item_key,
ConsistentRead=True|False
)On-Demand Mode
On-Demand Mode provides automatic scaling of read and write capacity, eliminating the need for manual capacity planning. However, it comes at a higher cost, approximately 2.5x more expensive than Provisioned Mode.
Partitions and Partition Throttling
In DynamoDB, a partition is a logical storage unit where data is organized based on the hash of the partition key. The partitioning system enables efficient data distribution and retrieval. Each partition holds a subset of the overall data, ensuring a balanced distribution across multiple partitions.
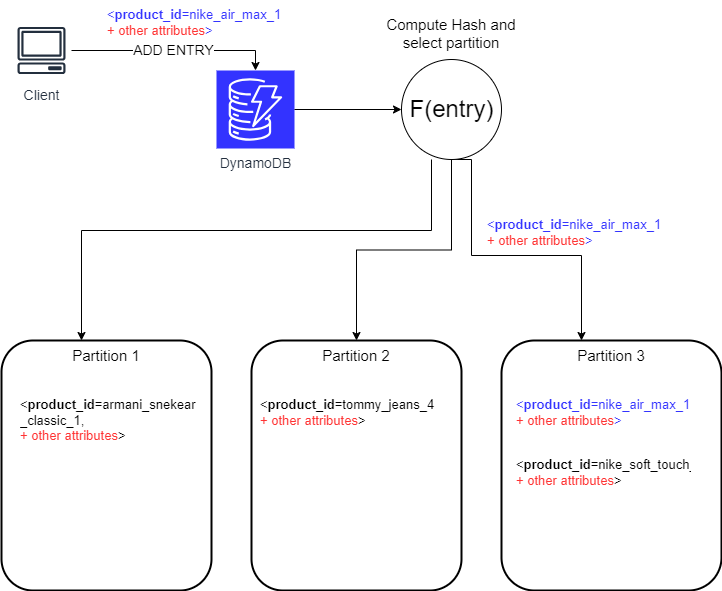
DynamoDB uses a hash of the partition key to determine where an entry is stored. This ensures a balanced distribution across partitions. However, challenges arise when multiple entries share the same hash, concentrating in a single partition. This is especially relevant for frequently accessed keys, like popular products in an e-commerce solution.
Effective partition key design is essential to avoid imbalanced data access. Further details on key design considerations can be found here. In particular is crucial to set a partition key that has the highest cardinality. Uneven distribution of read and write activity can lead to “hot” partitions, triggering throttling when exceeding 3000 RCU or 1000 WCU. Throttling negatively impacts performance.
Refer to DynamoDB documentation here for detailed insights into key design considerations. Selecting a partition key with the highest cardinality enhances scalability and efficiency. By addressing hot partitions through thoughtful design and ensuring high cardinality, developers create a robust foundation for scalable and efficient data storage and retrieval.
Indexes: LSI and GSI
One notable limitation of DynamoDB is that when querying data, you must use either the partition key or sort key to execute efficient and optimized queries. If you use other parameters than the primary key for filtering in DynamoDB queries, the filtering is performed client-side, which can indeed consume a significant amount of Read Capacity Units (RCUs) and may not be optimal for performance.
Utilizing Indexing Strategies to Enhance DynamoDB Query Performance:
GSIs provide the flexibility to query data across multiple partitions, making it possible to support diverse query patterns. They come in handy when your application demands different query patterns than the table’s primary key.
In DynamoDB, optimizing query performance is crucial, and two powerful indexing strategies – Local Secondary Index (LSI) and Global Secondary Index (GSI) – offer valuable enhancements. Here’s a breakdown:
Local Secondary Index (LSI):
- Purpose: Enhances query speed by introducing an alternate sort key while keeping the partition key unchanged.
- Addition Constraints: Can only be added during table creation, supporting up to 5 secondary indexes per table.
- Sort Key Attributes: Must be scalar attributes (string, number, or binary); lists are not supported.
- Throttling Consideration: LSI queries do not introduce throttling concerns since they operate within DynamoDB’s server environment.
- Implementation: Enables efficient querying using the new sort key on DynamoDB servers.
Global Secondary Index (GSI):
- Purpose: Accelerates queries by introducing an alternate primary key, offering flexibility in choosing partition and sort keys.
- Addition Flexibility: Can be added or modified after table creation, providing adaptability to changing requirements.
- Provisioned Throughput: Requires provisioning Read Capacity Units (RCUs) and Write Capacity Units (WCUs) for the GSI, impacting cost considerations.
- Throttling Impact: Write throttling on the GSI can affect the main table; careful GSI selection is important.
- Consideration: Requires strategic planning to balance improved query performance against the associated provisioning costs.
Choosing between LSI and GSI depends on your specific use case and scalability requirements.
Some Other DynamoDB features
DynamoDB Streams
DynamoDB Streams provide a time-ordered sequence of item-level modifications, enabling real-time data capture and change tracking.
Key Aspects of DynamoDB Streams:
- Change Tracking: Streams capture every modification to the table, including inserts, updates, and deletes, enabling real-time change tracking for the entire dataset.
- Event-Driven Architecture: Streams enable the creation of event-driven architectures by allowing developers to trigger AWS Lambda functions in response to specific changes in the DynamoDB table.
- Data Replication: DynamoDB Streams facilitate data replication across multiple tables or even different DynamoDB regions, supporting scenarios where data needs to be duplicated for backup or analytics purposes.
Time to Live (TTL)
DynamoDB offers a TTL feature that allows developers to define a specific timestamp attribute for each item. Items that exceed this timestamp are automatically deleted. This feature is particularly useful for managing data retention policies and automatically purging stale records.
- TTL Configuration: Developers can add an attribute to an entry specifying the time to live, and in DynamoDB settings, set the time to live and specify the attribute that DynamoDB should consider to check if the TTL of the entry is expired.
PartiQL: SQL-Compatible Query Language
PartiQL, is a SQL-compatible query language designed for querying structured and semi-structured data. DynamoDB supports PartiQL, allowing users familiar with SQL to seamlessly interact with the database. This feature simplifies querying and enables a more intuitive experience for developers.
PartiQL allows you to use SQL-like syntax for querying DynamoDB, making it easier for developers to transition from traditional relational databases to DynamoDB.
Conclusions
In wrapping up our exploration of Amazon DynamoDB, we’ve seen that while On-Demand Mode is straightforward and easy to use, getting the most out of Provisioned Mode may require a bit more fine-tuning. Balancing Read and Write Capacity Units, designing efficient tables and keys, and understanding the intricacies of provisioned throughput can optimize costs and enhance performance. DynamoDB, with its flexibility, provides a powerful platform whether you prefer the simplicity of On-Demand or the precision and cost effectiveness of Provisioned Mode.


